

Imho, when it comes to likert-type data, the only reasonable way to make nil-hypotheses tests (like in standard regression outputs) semantically meaningful is to center the data beforehand. Not standardizing, most people can't read that correctly.
If you center, you can always interpret deviation from the mean, which is somewhat of a built-in feature, considering it is the backbone of estimation in many cases.
#rstats #stats
Recent searches
Search options

Administered by:
#RStats
140 posts119 participants11 posts today

Want to Work with Data? You NEED SQL!
 Learn how to retrieve, filter, and manipulate databases efficiently
Learn how to retrieve, filter, and manipulate databases efficiently
 Speed up workflows & reduce dependency on others
Speed up workflows & reduce dependency on others
Choose your path: SQL with Python or R
 April 15, 2025 – 6 hours, online
April 15, 2025 – 6 hours, online
#Rstats #BigData #SQL #R #Python
https://www.jumpingrivers.com/training/public/

www.jumpingrivers.com · Public Training CoursesWe offer training in multiple programming languages for all levels, both online and in-person. Whether you're just starting out and need an introduction, or want to learn some more advanced programming techniques, take a look at our upcoming public training.

Is there a good example for an R packages that runs regular performance benchmarks (maybe even as some sort of regression tests)? #rstats



 Nous aurons le plaisir d’accueillir Maëlle Salmon @maelle, Research Software Engineer, qui partagera son expertise sur Git.
Nous aurons le plaisir d’accueillir Maëlle Salmon @maelle, Research Software Engineer, qui partagera son expertise sur Git.
 Vendredi 11 avril à 12H CEST
Vendredi 11 avril à 12H CEST #Zoom
#Zoom Plus de détails et RSVP : https://www.meetup.com/rladies-paris/events/307063402/
Plus de détails et RSVP : https://www.meetup.com/rladies-paris/events/307063402/
#RStatsFr #RStats #RLadies #VersionControl #Git @RLadiesGlobal


 2025 #30DayChartChallenge | day 04 | comparison | big or small
2025 #30DayChartChallenge | day 04 | comparison | big or small
.: https://stevenponce.netlify.app/data_visualizations/30DayChartChallenge/2025/30dcc_2025_04.html
.
#rstats | #r4ds | #dataviz | #ggplot2
 and NCHS (184 datasets, 14.6%), which together represent over a third of all preserved data. Other significant categories include Vaccinations (78 datasets), Public Health Surveillance (68 datasets), and 500 Cities & Places (57 datasets). Smaller categories include Policy, Funding, and Health Statistics. A color gradient from light orange to dark purple indicates dataset size from smallest to largest.")

It's Day 4 of the #30DayChartChallenge, and the prompt is "Big or Small"
 Made a very minimalist chart using #RStats
Made a very minimalist chart using #RStats I'm now determined to use this same dataset for all 30 prompts
I'm now determined to use this same dataset for all 30 prompts


Minimalist population pyramid plots with base R, live in the browser:
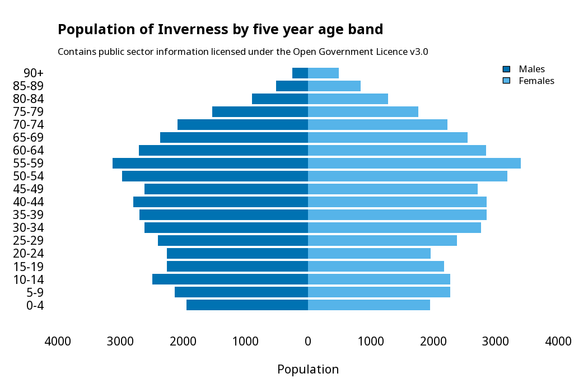
Data By John · Population pyramid plots with base RPopulation pyramids in the browser with shiny, and nothing else



#RStats Dev Diary:
Playing with some Forward Error Correction code - similar to par2 & Reed-Solomon codes.
I'm considering making a package.
What should the package on FEC (Forward Error Correction) be named?

So I'll totally post this on the @Posit community forum, but thought the #rstats crowd here might have some ideas... about this potentially daft question.
So I'm pretty new to using Posit Connect. All seems pretty straight forward, but I'm not an admin so hard to tell exactly what is going on or might have been borked in setting it up.
The problem is, I can deploy a .rmd document with source code and have it schedule, and I can render everything locally fine, but if I try to deploy a quarto doc with source code it fails saying there is no rmarkdown package, which seems... weird. But this screenshot from the console make me think there should be a universal install of knitr/rmarkdown on the server maybe?
Do I just need to get an admin to install the packages? It seems so weird because packages (including knitr/rmarkdown) seem to be installing in the deploy process...

rmarkdown: (None)")
There are 11 new #rstats packages on CRAN:
- 36.36% are in English.
- 0.00% are in other languages than English.
- 0.00% use multiple languages.
- 63.64% do not declare any language.

 for(i in seq_along(data)) value[[i]] = data[[i]][1]
for(i in seq_along(data)) value[[i]] = data[[i]][1] lapply(data, function(x) x[1])
lapply(data, function(x) x[1]) lapply(data, \(x) x[1])
lapply(data, \(x) x[1]) lapply(data, `[`, 1)
lapply(data, `[`, 1)

Any  folks know how to install TinyTex into a Debian / Ubuntu image globally? The installer script (https://yihui.org/tinytex/#installation) doesn't work see related (https://github.com/rstudio/tinytex/issues/415)
folks know how to install TinyTex into a Debian / Ubuntu image globally? The installer script (https://yihui.org/tinytex/#installation) doesn't work see related (https://github.com/rstudio/tinytex/issues/415)
yihui.orgTinyTeX - Yihui Xie | 谢益辉TinyTeX is a custom LaTeX distribution based on TeX Live that is small in size, but functions well in most cases, especially for R users. If you run into the problem of missing LaTeX packages, it …

I'm looking for a good teaching dataset to discuss long and wide format data. Any suggestions?

# contexto: Atropellados en Costa Rica
# objetivo: Distritos-Año mas mortales
# proceso : Ordenar de mayor a menor
#Rstats #CostaRica Costa Rica #softwareLibre
GIF

#rstats Is there an existing tool to automate a repex->rpubs pipeline? My current manual workflow is make a reprex in an .R script, copy the contents over to a .qmd, and use the publish feature in the rstudio IDE.
Sometimes my reprexes get just a tad bit more complex and requires some prose to walk through the steps. In those cases I like publishing them as almost like standalone micro blogposts.
Ex: this reprex doc I made to show how to recover ggrepel coordinates https://rpubs.com/yjunechoe/ggrepel-recover-position
rpubs.comRPubs - Recover ggrepel drawn positions

R/Medicine 2025 workshop on "Personal R Administration"
Tips, tricks, tweaks, and some hacks for building #datascience dev environments handling new R versions, passwords in your R code, failed package installations and more!
Register now! https://rconsortium.github.io/RMedicine_website/Register.html


[blog] Throw-back Thursday!
Two years ago @MikeMahoney218 brought waywiser to rOpenSci.
Is this a package you use? Have any usecases you'd like to share?
 waywiser is Now a Part of rOpenSci April 4, 2023 https://ropensci.org/blog/2023/04/04/waywiser-is-now-a-part-of-ropensci/
waywiser is Now a Part of rOpenSci April 4, 2023 https://ropensci.org/blog/2023/04/04/waywiser-is-now-a-part-of-ropensci/

ropensci.orgwaywiser is Now a Part of rOpenSciPlus version 0.3.0 now on CRAN, and a new preprint

#rstats hivemind: would it be too funky to define a package version major.minor.patch.dev as YYYY.MM.DD.VERSION, i.e. map major to year, minor to month, patch to day, and leave the dev component for the actual version..? I'm thinking of a data package whose upstream data releases are versioned based on the date... anyone ever tried such heretic approach? Would CRAN maintainers be okay with this?! ;)
asking for a friend.